
Werk je binnen Cäsar met reistijden en afstanden? Gebruik je weleens een getalveld zoals het aantal klanten of de omzet per postcode? Of wat dacht je van het instellen van een doelgroep percentage of -index? Dan hebben we een toffe feature voor je !
Normaal stelde je een bepaalde reistijd in. Laten we zeggen 10 minuten. Dit was dan automatisch de maximale reistijd. Oftewel "kleiner dan of gelijk aan 10". Het instellen van een reistijd of afstand hebben we uitgebreid. Vanaf nu kun je voor iedere numerieke waarde binnen Cäsar bepalen of deze groter of juist kleiner moet zijn dan de waarde die je invult. Hoe werkt dit?
Selecties maken met POI data.
Binnen Cäsar kun je een gebied in kaart brengen op basis van POI's (Points of Interest). Het gebied kun je afbakenen door middel van reistijd of afstand. Tot voor kort kon je een reistijd of afstand ingeven door de maximum waarde te bepalen. Maximaal 10 minuten bijvoorbeeld. In database termen noemen we dat "Kleiner dan of gelijk aan 10". Maar de wereld verandert. En Cäsar ook!
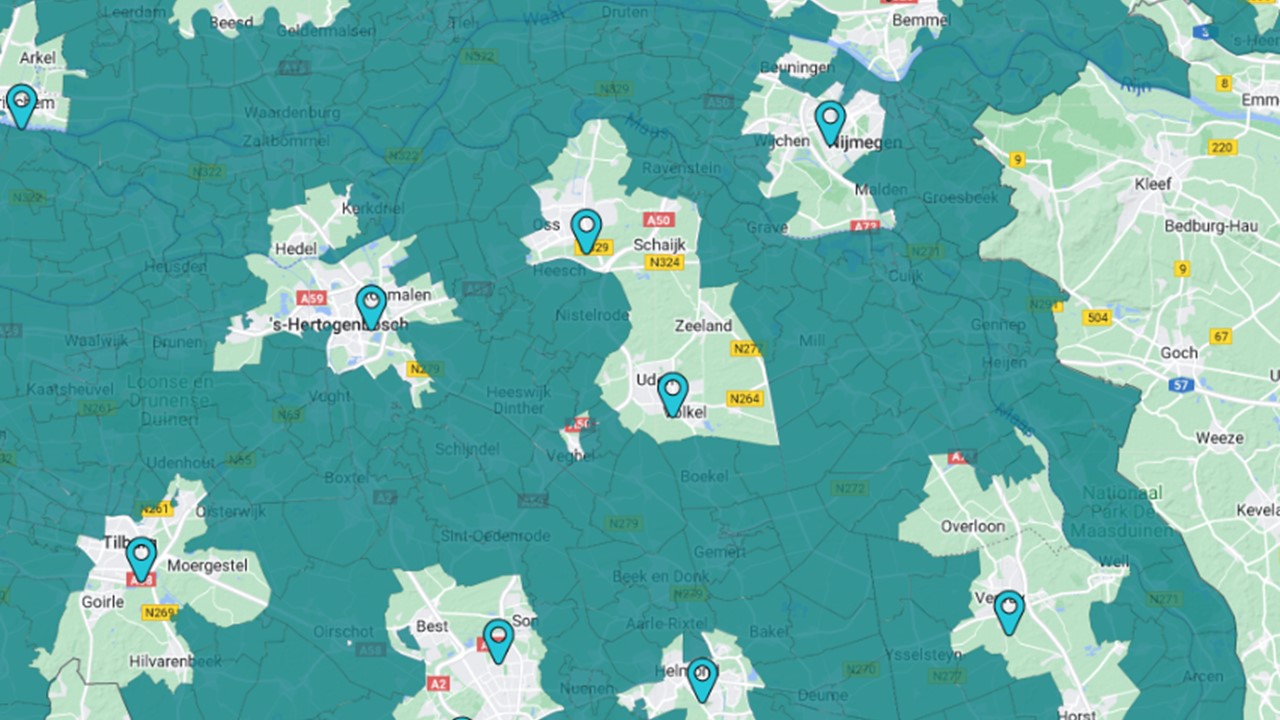
Vanaf nu kun je in combinatie met een POI ook aangeven dat een reistijd of afstand ook groter moet zijn dan 10 minuten (als rekenvoorbeeld). Dat betekent dus dat je het gebied tot 10 minuten gaat uitsluiten. Dat zul je ook zien in het kaartbeeld (zie onderstaand voorbeeld).
Aan de linkerzijde van de velden reistijd en afstand staat voortaan een zogeheten "operator dropdown". Daar vind je twee opties:">=" (groter dan of gelijk aan) en "<=" (kleiner dan of gelijk aan).
Selecties maken met doelgroepen.
Doelgroepen maken binnen Cäsar is een krachtig instrument en een waardevolle datastroom om je selecties te verfijnen. Heb je eenmaal je doelgroep gedefinieerd, dan kun je als volgende stap gebieden gaan selecteren waar je doelgroep in een bepaalde mate aanwezig is. Dit kun je doen op het aanwezigheidspercentage of de index. Die laatste geeft aan of een gebied beneden of boven het landelijk gemiddelde scoort. Handig !
Tot op heden kon je bijvoorbeeld bij index het getal 100 invullen. Dat betekent dat alle gebieden worden geselecteerd die een minimale index hebben van 100. In database termen noemen we dat "Groter dan of gelijk aan 100". Vanaf nu kun je ook de selectie maken om alle gebieden te selecteren die beneden de indexwaarde van 100 liggen. "Kleiner dan of gelijk aan 100". Wat is de gedachte hierachter? Een argument bij doelgroepen is dat je juist de gebieden wilt selecteren waar je doelgroep in mindere mate aanwezig is en je juist hier middelen in wilt gaan zetten voor communicatie.
Aan de linkerzijde van de velden score en index staat voortaan een zogeheten "operator dropdown". Daar vind je twee opties: ">=" (groter dan of gelijk aan) en "<=" (kleiner dan of gelijk aan).
Selecties maken met eigen data (themadata).
Een onderschatte functionaliteit binnen Cäsar. Eigen data. Erg mooi en vooral een slimme manier om je campagnegebied mee te definieren. We noemen dat themadata omdat je zelf kan bepalen welk onderwerp je op de kaart wilt zetten en hoe je filters gebruikt. Deze kaartlaag is vergelijkbaar met de doelgroepthema's en het bekende doelgroep kaartbeeld. Themadata wordt gebruikt in de sectie "Geografie" en kun je zelf aanbieden door op het plustkeken te klikken en voor "Thema data" te kiezen.
Als je getalvelden in je eigen dataset hebt staan (bijvoorbeeld het aantal abri's, het aantal klanten of de omzet per postcode), dan kun je hier ook op selecteren en dus filteren (zie de onderstaande afbeelding).
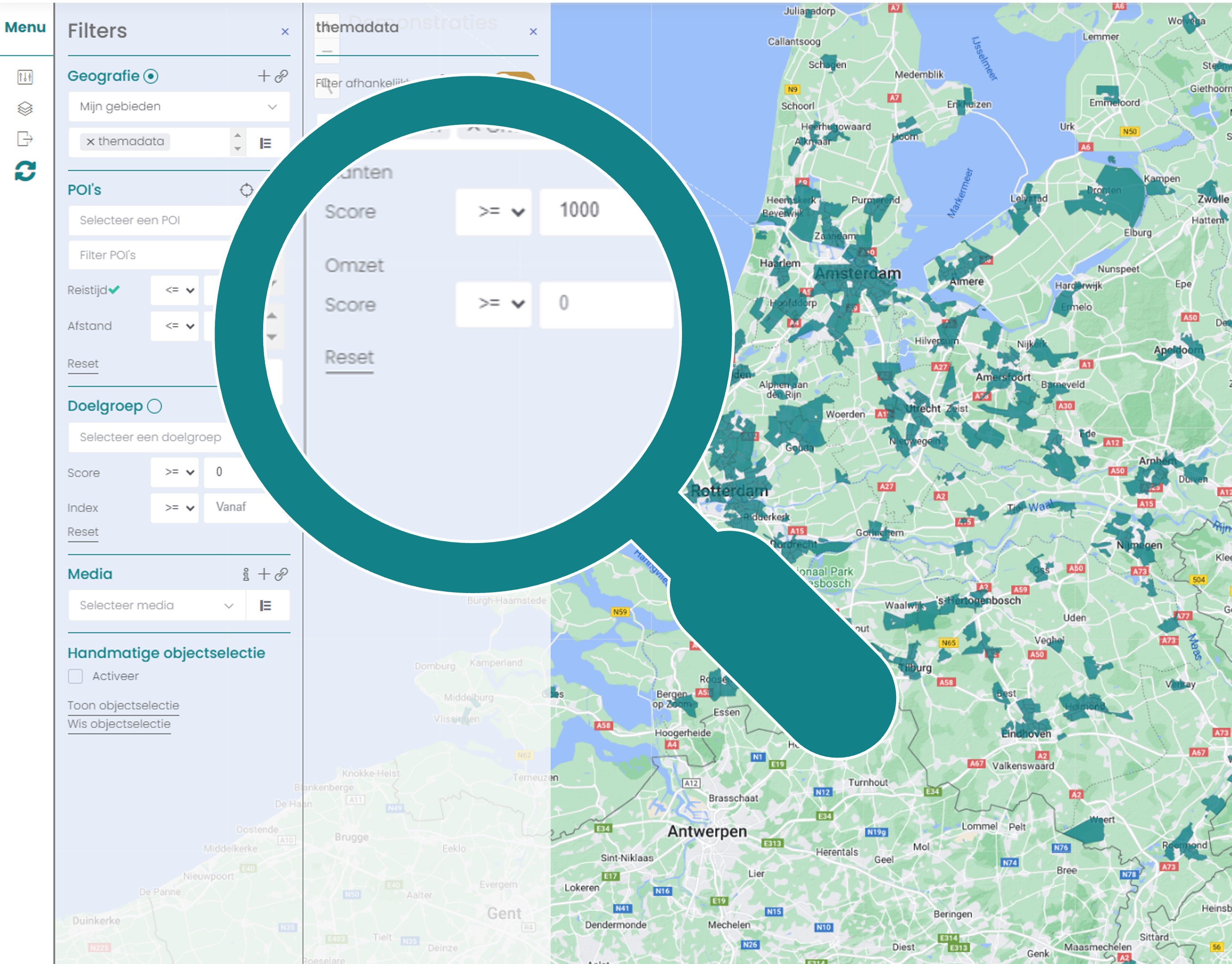
In de bovenstaande afbeelding hebben we aangegeven dat we alle postcodes willen selecteren waar meer dan 1.000 klanten staan geregistreerd. Je kan dit dus ook andersom doen, door juist alle postcodes te selecteren waar minder dan 1.000 klanten staan geregistreerd. Dat laatste kan je bijvoorbeeld combineren met een doelgroepselectie. Door gebieden te selecteren met minder klanten en gebieden met relatief veel doelgroep. Bij ieder getalveld zul je voortaan de operatorvelden zien met de keuzes "<=" en ">=".
Met het toevoegen van deze functionaliteit ben je nog beter in staat om je selecties krachtiger te maken en te verfijnen. Maar bovenal kun je de verschillende datatypes nog beter met elkaar combineren.